之前(https://ithelp.ithome.com.tw/articles/10330192)我們有稍微提到AlexNet利用了與以往不同的激勵函數來避免梯度消失的問題,不過那時並沒有詳細的說明甚麼是激勵函數,以及梯度消失是甚麼問題,今天就讓我們來回答這些疑惑!
在MLP的討論中(https://ithelp.ithome.com.tw/articles/10322151),我們有提到激勵函數的靈感來源,一來是模擬生物神經元的運作方式,二來,在數學中,我們很難用「完全線性的模型」來預測真實世界的問題,所以我們需要加點魔法進去,這個魔法就是「非線性」,也就是激勵函數帶來的好處。
如果不清楚甚麼是線性甚麼是非線性的話,可以稍微想一下一個畫面:你在一張空白紙上隨便點很多個黑點,接下來你需要使用一條直線跟一條會彎曲的線,將所有黑點分成兩個區塊,直線對應的就是「線性」,會彎曲的線對應的就是「非線性」。從這個例子中我們可以看出來,現實世界中有許多問題都是非線性的,所以如果一個線性模型只能產生線性的結果的話,很難處理現實世界中的問題。
之前我們提到激勵函數的時候都是以概念為主,現在讓我們就著公式與函數圖形仔細的研究一下吧!
激勵函數一般有幾個特徵:非線性與可微分,前者上面說明過了,後者是因為激勵函數也是模型當中的一員,所以如果利用反向傳播(梯度下降)更新參數的時候,這個更新的資訊也會經過激勵函數,因此需要計算激勵函數的微分。
激勵函數可以按照其函數特性分成飽和激勵函數與非飽和激勵函數,主要的分類依據在於是否會隨著輸入訊號的改變而使函數的輸出值飽和。非飽和函數相較於飽和函數,除了可以加速模型的收斂速度以外,也可以避免梯度消失的問題,這個我們下面會解釋。除了飽和與非飽和以外,我們還可以關注這個激勵函數的輸出結果是否是以0為中心的對稱函數,如果不是的話,可能會使模型參數更新時產生額外的偏差(Bias)。
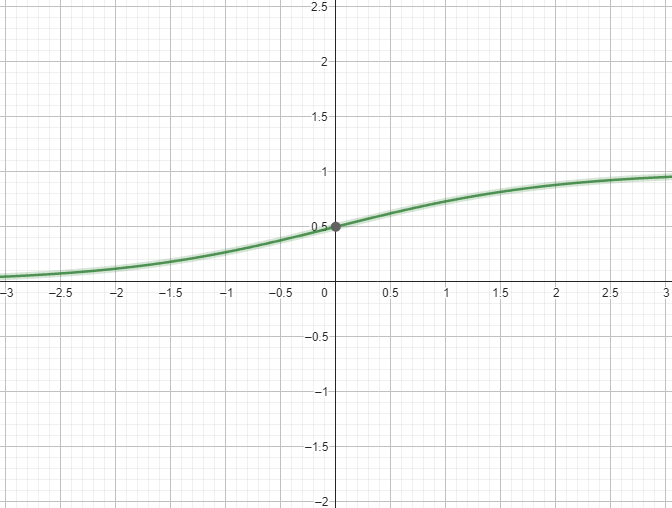
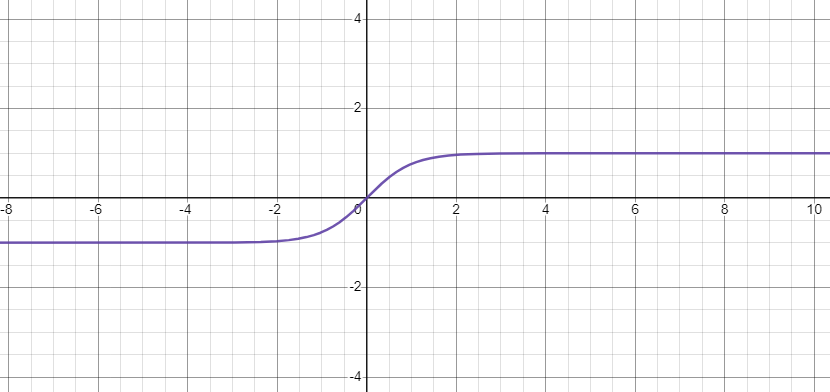
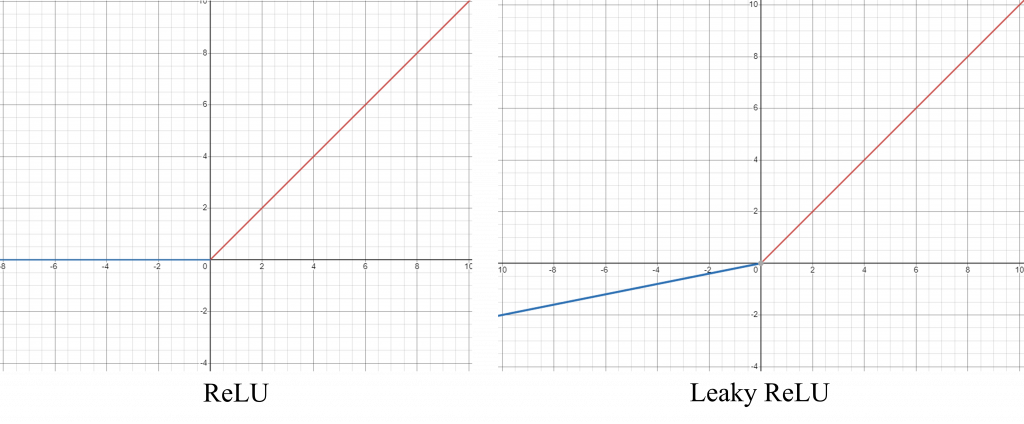
這邊提供了常見激勵函數的列表可以參考:https://zh.wikipedia.org/zh-tw/%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0 ,大家可以觀察一下每個函數的值域與定義域,並且看一下每個函數的微分長甚麼樣,值得注意的一點是,我們通常不太使用太複雜的激勵函數,因為這樣我們可能會需要話很多時間計算激勵函數與他的微分結果,會導致訓練時間變長。


 iThome鐵人賽
iThome鐵人賽